Archive of ‘Reading Reflections’ category
With an abundance of heavily weighted essays to complete as well as birthday festivities, I ran short of time to analyse this week’s reading. Here are a few key take aways nonetheless:
‘The most extensive computerised information management system existing today is the Internet. The Internet is a global distributed computer network.’
‘Prior to its usage in computing, protocol referred to any type of correct or proper behaviour within a specific system of conventions’
‘At the core of networked computing is the concept of protocol. A computer protocol is a set of recommendations and rules that outline specific technical standards.’
‘The protocols that govern much of the Internet are contained in what are called RFC (request For Comment) Documents,’ of which are ‘published by the Internet Engineering Task Force.’
‘Other protocols are developed and maintained by other organisations.’ For example the World Wide Web Consortium was created to ‘develop common protocols such as Hypertext Markup Language (HTML) and Cascading Style Sheets.’
‘Now, protocols refer specifically to standards governing the implementation of technologies.’
This week’s reading revolved around the ‘poetics, aesthetics, and ethics’ of the Internet as a database. So what is a database? The standard definition of the term is a ‘structured collection of data,’ however this model can vary (hierarchical, network, relational, and object-oriented) from one instance to another.
New media technologies are recognised for often adopting a database structure, rather than a linear, narrative form. Immediately, the hypertext system of the Internet springs to mind. Like a database, a webpage is made up of a coded, HTML file which consists of a sequential list of instructions for individual components. This material then correlates to what we view online – a collection of items such as text, imagery, video and links to other pages. They could not exist without the specific coding in the HTML file, as one tiny mis-type could result in a significant error. In this sense, HTML coding is much like human DNA, in which sequencing of nucleotides code for specific traits on the body. Does this mean human genetics can be classed as a database system?
I think where they differ is the fact that webpages are continuously unfinished and infinitely changing. HTML files have the capacity to be edited post publication on the Internet – new content or links might be added. This is another feature of a database to which the Internet complies, whereas the human genetics system does not. The DNA we are born with remains our DNA for life, and generally we cannot alter it.
I know this is only the tiniest slice of what the reading was about, but it was just an interesting comparison that came to mind.
Whilst I realise the relevance of this text to the Internet’s networked system, I purposefully chose not to study physics and mathematics to avoid content like this! Somehow it has managed to work its way into my communications degree and I can safely say I am not a fan!
Putting my frustrations aside, I attempted to make sense of the information that this reading divulged. It firstly discusses Pareto’s 80/20 rule, a model sparked by the simple observation that ‘ 80% of his peas were produced by only 20% of the peapods.’ This rule has been found to apply to a wide range of other truisms, in and out of nature.
To my understanding, the 80/20 rule, when graphed mathematically, forms a ‘power law distribution.’ Unlike a random network, which is represented by a traditional bell curve, a power law distribution does not have a peak, and instead forms a continuously decreasing curve, implying that ‘many small events coexist with a few large events.’ This is supposedly the distinguishing feature of a power law. This diagram, sourced from the reading, really explained it for me:
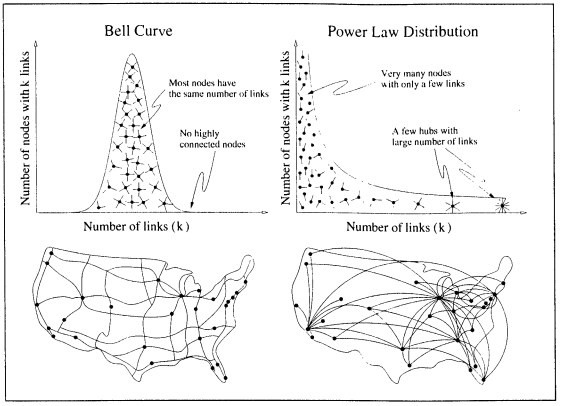
So what does this have to do with the networked system of the Internet? Although I’m still attempting to get my head around this myself, here’s my understanding. It has recently been discovered that networks, like that of the Internet, do in fact follow a power law system, when previously thought to assume an entirely random structure.
The academics who discovered this used ‘a little robot’ (not sure if that means a literal little robot or something else too sciencey for my comprehension) to map out the nodes and links behind the Web and understand the complexity of it’s network once and for all. Whilst they assumed that the majority of documents would be equally popular, it was instead found that there were many nodes with a few links only, and a few ‘hubs’ with a extraordinary amount of links. This indicated for the first time that networks are far from random.
To me, this seems logical and I’m not sure why it was such a surprise to these academics. There are SO many websites out there that I would assume the majority of them would encounter minimal traffic, resulting from their mere number of links to other ‘nodes’ or webpages. But co-exisiting with these are a few immensely popular websites, like Facebook for example, that have millions of visitors each day due to their greater amount of links.
Am I missing something, or is it that simple?
So unfortunately I ran out of time last week to properly reflect on the reading this week… But here are a few key take aways:
‘How does individual behaviour aggregate to collective behaviour?’
‘What makes the problem hard, and what makes complex systems complex, is that the parts making up the whole don’t sum up in any simple fashion. Rather they interact with each other, and in interacting, even quite simple components can generate bewildering behaviour.’
By network, we ‘could be talking about people in a network of friendships, or a large organisation, routers along the backbone of the Internet or neurons firing in the brain. All these systems are networks.’
‘Real networks represent populations of individual components that are actually doing something – generating power, sending data or even making decisions.’
‘Networks are dynamic objects not just because things happen in networked systems, but because the networks themselves are evolving and changing in time, driven by the activities or decisions of those very components.’
This week’s text by Andrew Murphie and John Potts revolves around the different perspectives of how the technology affects culture. To set my view in context, here’s the background you need to know:
- ‘Technological determinism refers to the belief that technology is the agent of social change.
- Technological determinism tends to consider technology as an independent factor, with its own properties, its own course of development, and its own consequences.
- Technical innovation will generate a new type of society’
I find it very surprising that anyone could assume an entirely technologically determinist view when it excludes so many factors that can contribute to cultural change.
It should first be made aware that technological innovation is usually firstly instigated by a demand and/or desire from society, or as inspired by something that already exists. When you think about it, each new technology that we use today is basically a ‘new and improved’ derivative of something that is pre-existing and used. If a product or it’s particular features prove to be successful amongst the public, this in itself indicates to innovators that a market already exists for the idea. Innovators would surely then undertake extensive market research in order to predict if their proposed product has the potential to take off. They must assess what features and trends are successful on other platforms and consider the wants, needs and changing relationships that consumers have with technology.
With this is mind, it is already clear that society and culture essentially drive the innovation of new technology. Whilst I don’t deny that once products can have an influence over a culture once they become available, it is important to note that technological development is fuelled by their behaviour in the first place. I feel like this factor pretty much rules out the technologically determinist view all together, as you can always trace the evolution technology back to society. Technological determinists seriously need to consider the fact that technology is not just changing us, but we are changing technology.
For weeks now we have been exploring the theory and practice of hypertext: its origin, evolution, affordances and limitations. This week’s reading by Jane Yellowlees Douglas raises yet another new aspect of the medium to consider – that is, hypertext fiction.
As we have established in previous lectures and readings, traditional print texts contain a sequential, linear narrative, encompassing a defined beginning, middle and end, and generally the author intends for the story to be interpreted in one single way. Conversely, hypertext narratives, according to Douglas, consist of discrete segments of text (in the form of pages, sites or windows) which are associated by links. The ‘reader’ is active in that they have control over which path to take, and much of their understanding comes from the relationship between the segments of text they have chosen. No user experience is the same, and up to hundreds of possible versions of the text are inevitably created.
Interestingly, the text was written in 2000 and revolves around Douglas queries’ about the usage rates of print and hypertext fiction in the future. The way hypertext fiction was discussed about made it seem as though it was the next ‘big thing,’ not necessarily ruling books out of the picture, but certainly increasing in popularity. This left me a bit confused however, as I don’t think I had ever ‘read’ a traditional hypertext fiction myself. Thus, I deemed it necessary to jump on that bandwagon, and experience the unknown in order to give me a better understanding. I attempted to find the renowned ‘afternoon, a story,’ by Michael Joyce, but failed to find a version compatible with my computer. I branched out in searching for a hypertext fiction of any kind, but again didn’t have much luck. Instead, I came across the following article:
http://www.salon.com/2011/10/04/return_of_hypertext/
Author, Paul La Farge, discusses how and why the hypertext fiction did not find it’s place in society, with the last piece to be found have being published back in 2001. Perhaps it was ‘born into a world that wasn’t quite ready for it,’ or maybe it was found to be too difficult for authors to compose.
Assuming this information is accurate (however I’m sure Adrian will correct me if misinformed), many of Douglas’s interactive narrative based theories are now outdated. Whilst it sounded like an scheme with serious potential, it is interesting to see how some ideas seem to fail to launch. This is not to say however that hypertext in other forms was unsuccessful – I am purely considering it with this style of hypertext fiction in mind. No hate!
The week five reading by George Landow addresses all things hypertext – the nature of the concept, it’s impact on society and the like. Just a quick disclaimer: due to my sleep deprivation, lack of energy, and never-ending pile of assignments, I’m going to keep this post short and sweet!
Amidst Landow’s outline of the limitations of the terminologies used to describe hypertext, the following quote stood out to me:
“Additional problems arise when one considers that hypertext involves a more active reader, one who not only chooses her reading paths but also has the opportunity (in true read-write systems) of reading as someone who creates text; that is, at any time the person reading can assume an authorial role and either attach links or add text to the text being read.”
Consequently, it is arguable that the title of a ‘reader’ is an inappropriate term to use to label an individual who engages with online content. Hypertext ultimately enables a more meaningful and in-touch relationship between the producer and consumer. The ‘readers’ of hypertext can instantaneously respond to other’s works, by linking out to them in a blog post, or through simply posting a comment on their content. The individual who goes to these lengths is certainly doing a lot more than just reading – as Landow put it, they ‘assume an authorial role.’ Perhaps Axel Bruns’ ‘produser’ (mash between producer and user) would also be a sufficient description.
This level of interactivity enabled by hypertext is not as easily achieved between say the reader of a physical novel and its author alone. You can’t scribble a ‘comment’ in the back page of a novel for the author to receive… If you ‘link’ out to an author in an journal entry, they, nor anyone else, will have no awareness of your attempt to connect. But once you put the book down and open a web browser, you now can tweet at John Green to tell him how The Fault In Our Stars changed your life.
We can all thank hypertext for this ideal.
This weeks reading by Theodor Nelson is really quite astounding. Published in 1992, Nelson proposes a stream of theories and predictions based on hypertext and computer technologies for the future. Although some concepts raised were quite difficult to comprehend, it is very interesting to compare his speculations to our current means of technology and usage.
Seemingly, during the period of authorship, the entire field of technology and computing systems was a bit of a mess. The design and functional properties of computers at the time was extremely disorganised and opened ‘whole new realms of disorder, difficulty and complication for humanity.’ Whilst some attempted to embrace the new technology, many others were hateful towards it and were hopeful that the notion wouldn’t take off.
Nelson however developed his own approach to the matter. He claimed that these problems would be solved if attention was directed to the re-design and simplification of the technology. This, in turn, would create a more user-friendly experience and provide knowledge across platforms via hypertext.
He then delves into is the concept of ‘Project Xanadu,’ which was something I’d never heard of. He explains the project as a ‘hyper-text system to support all the features of these other systems.’ Xanalogical structure was based upon one pool of storage that can be shared and simultaneously organised in many different ways. This ideal sounds much like the fundamentals of the Internet, which makes me wonder if the later birth of the Internet in 1989 was an expansion off Xanadu Sytem or if the Internet instead dominated the idea of Xanadu out of the picture.
The section that struck me the most was ‘The 2020 Vision.’ The following excerpt is particularly remarkable:
“Forty years from now (if the human species survives), there will be hundreds of thousands of file servers—machines storing and dishing out materials. And there will be hundreds of millions of simultaneous users, able to read from billions of stored documents, with trillions of links among them”
Nelson is scarily accurate. For one, the human species have survived – hooray! But we are also living within this digital age, surrounded by these ‘machines’ that offer us a world of information at our fingertips. According to Internet World Stats, the system is an infinite resource containing almost a billion websites (not to mention pages) and there are currently seven billion avid Internet users across the globe. It is amazing to consider the dramatic proliferation that technology has undergone in such a short span of time, and how on Earth Nelson was able to predict this with such accuracy almost forty years prior. It is hard to imagine how much more advanced it can get in the next forty years, but I am so curious and excited to find out!
Technology is awesome. That is all.

Of the three readings this week, Paul Graham’s ‘The Age of the Essay’ pleasantly and ironically surprised me. I’ve personally always loved writing – expressing myself, communicating with others and exploring ideas that interest me in a critical way. But give me the task of writing an essay based on classical literature, and I couldn’t think of anything worse.
Why is it that the subject of English language has become forever associated with ancient texts? As Graham discusses, it is basically the result of a ‘series of historical accidents.’ European classical scholars began the tradition almost a thousand years ago when they re-discovered the texts we now know as ‘classics.’ The work and careers of these scholars revolved around these texts, and although their studies were fascinating and prestigious at the time, they have since declined in relevance and importance.

So why has the study of classical literature since remained a core part of the school curriculum? Essentially, this out-dated and seemingly useless teaching method has stuck around because we are inherently copycats, mimicking the ways of those who are academically ‘higher’ than us. Students are imitating the ways of English professors, and English professors imitating the work of classical scholars. It seems pretty ridiculous when you think about it that way.
What’s intriguing is that many of us would never question why it was that we were writing essays on these redundant texts. It has been the norm of the education system for some 700 years, and despite the generalised dislike towards actually doing it, it is rare that someone would query ‘why.’
In my view, good writing comes from individual interest and fascination in a subject. Classical literature is personally not my cup of tea, and thus essay writing on its basis was never something that enthused me during high school. A lack of interest results in a lack of motivation, and a lack of motivation leads to poor writing. Not to mention the painful process of stringing together a dreary essay just because you have to.
It is interesting to relate Graham’s article to Adrian’s ideas of network literacy. Maybe the underlying point here is that we need to modernise the means of English teaching in line with our current technological-driven society. Instead of enforcing essay writing on ancient texts, maybe it should be replaced with the encouragement and tuition of blogging on an area of personal interest. For me personally, and I’m sure many will agree, it is a much more rewarding experience after all.
Check out Paul Grahams article here and Adrian’s piece on network literacy here! Both are worth a read.
The frightful world of copyright is something we must be aware of as online publishers. Adhering to the rules of copyright is not only Internet etiquette, but can also save you from a nasty court case. Just on that note, I’d like to make an official disclaimer in saying that if I happen to post any copyright material (and if I do so, I didn’t know, I swear!), please don’t hesitate to let me know and I will happily take it down. Last thing I need right now is to be sued… So please, let’s just be friends and forget it ever happened!
Back on track. Wouldn’t it be great if there were a system where content creators could give consumers them permission in advance to share and re-use their work? Thankfully, there is! It’s known as Creative Commons, and this in fact was the subject of our weekly readings. Basically, Creative Commons is an online licencing system in which the creator offers their permission for their work to be used by others, in accordance with certain standardised guidelines that they themselves determine. The elements of Creative Commons are as follows:
- Attribution: The user must acknowledge the content creator.
- Non-commercial: The user can not make any financial gain by using the creators work.
- No derivatives: This means that the creator has not given permission for the user to alter their work.
- Share-alike: New creations that use the material must use the same licensing terms.
Creative commons licenses always attain the Attribution condition, but it is the creator’s choice to pick and choose which of the other elements apply to their work. Therefore, the less elements chosen, the more freedom the user has; the more elements chosen, the less freedom the user has. I think Creative Commons is a great system, especially for media students like myself, as it allows content to be shared and used in a legal and friendly way. You go, Creative Commons!
